Pandas快速入门指南:CSV操作与数据清洗核心
Pandas快速入门指南:CSV操作与数据清洗核心
Pandas是Python中最强大的数据处理库。它的核心数据结构是DataFrame(二维表)和Series(一维数组)。

1. 基础环境准备
首先,确保已安装Pandas并导入它:
Python
1 | |
2. CSV文件操作
这是数据分析中最常见的起点。
2.1 读取CSV文件
使用pd.read_csv()将CSV文件内容加载到DataFrame中。
| 函数/方法 | 描述 | 常用参数 |
|---|---|---|
pd.read_csv(filepath) |
从文件路径读取数据 | sep=',' (分隔符), header=0 (行号作列名), encoding='utf-8' (编码), index_col=None (指定列作索引) |
其他参数具体见:Pandas CSV 文件 | 菜鸟教程
示例:
Python
1 | |
2.2 写入CSV文件
使用df.to_csv()将DataFrame内容写入CSV文件。
| 函数/方法 | 描述 | 常用参数 |
|---|---|---|
df.to_csv(filepath) |
写入到文件路径 | sep=',' (分隔符), index=True (是否写入行索引), header=True (是否写入列名) |
示例:
Python
1 | |
3. 数据初探与概览
在清洗之前,需要快速了解数据的结构和质量。
| 函数/方法 | 描述 |
|---|---|
df.head(n) |
查看前n行数据(默认n=5) |
df.tail(n) |
查看后n行数据(默认n=5) |
df.info() |
打印DataFrame的概要信息,包括数据类型、非空值数量、内存占用等 |
df.describe() |
计算数值型列的描述性统计信息(计数、均值、标准差、最小值、最大值和四分位数) |
df.shape |
返回DataFrame的维度(行数, 列数) |
df.dtypes |
返回每列的数据类型 |
示例:
Python
1 | |
4. 数据清洗常用函数
数据清洗的目标通常是处理缺失值、重复值和数据类型转换。
4.1 Pandas 清洗空值
4.1.1 删除空行(列)
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
1 | |
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=’all’ 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
[!NOTE]
注意:默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数
我们可以通过 isnull() 判断各个单元格是否为空。
1 | |
以上实例输出结果如下:
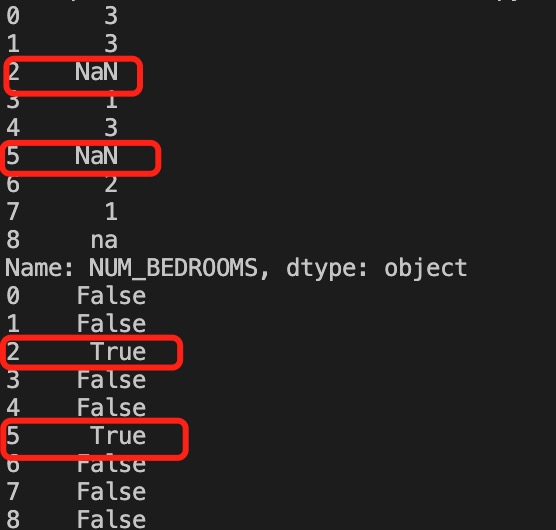
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
1 | |
以上实例输出结果如下:
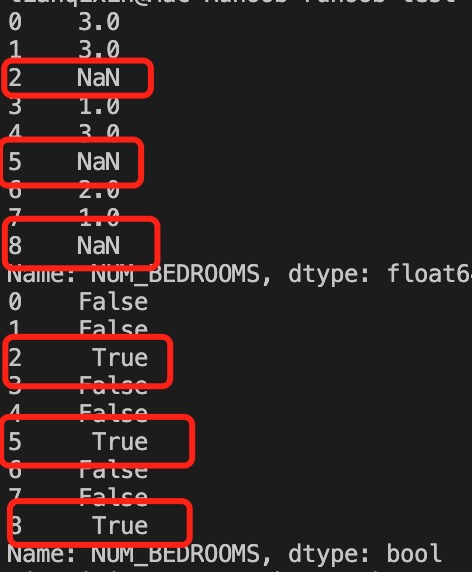
4.1.2 填充空值
| 函数/方法 | 描述 | 常用参数 |
|---|---|---|
df.fillna(value) |
用指定值填充缺失值 | method='ffill' (向前填充), method='bfill' (向后填充); inplace=True (直接修改原DataFrame) |
示例:
1 | |
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
4.2 删除重复数据
| 步骤 | Pandas 方法 | 描述 | 示例代码 | 常用参数 |
|---|---|---|---|---|
| 检查 | df.duplicated() |
返回布尔 Series,判断行是否重复。 | print(df.duplicated().sum()) |
keep='first' (保留第一个出现), keep='last' (保留最后一个出现), keep=False (所有重复项都标记为True) |
| 删除 | df.drop_duplicates() |
删除重复的行,默认保留第一次出现的记录。 | df.drop_duplicates(inplace=True) |
keep='first' (保留第一个出现,默认), keep='last' (保留最后一个出现), keep=False (所有重复项都标记为True) |
| 基于子集删除 | df.drop_duplicates(subset=...) |
只基于特定的几列来判断是否重复。 | df.drop_duplicates(subset=['ID', 'Date'], keep='first', inplace=True) |
1 | |
4.3 数据类型转换
确保列的数据类型是正确的,例如将字符串转换为数值或日期。
| 函数/方法 | 描述 | 常用参数 |
|---|---|---|
df['col'].astype(dtype) |
将Series转换为指定的数据类型 | dtype='int', 'float', 'str' ,‘np.float3’ |
pd.to_numeric(series) |
将Series强制转换为数值类型 | errors='coerce' (无法转换的会变为NaN) |
pd.to_datetime(series) |
将Series转换为日期时间类型 | format (指定日期格式) |
df['New_Unit'] = df['Old_Unit'] * 0.4536 |
直接对 Series 进行数学运算 |
1 | |
4.4 清洗错的离谱的数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据:
1 | |
以上实例输出结果如下:
1 | |
也可以设置条件语句:
将 age 大于 120 的设置为 120:
1 | |
以上实例输出结果如下:
1 | |
也可以将错误数据的行删除:
将 age 大于 120 的删除:
1 | |
以上实例输出结果如下:
1 | |
4.5 类别数字编码
4.5.1 one-hot编码(独热编码)
独热编码(One-Hot Encoding),又称一位有效编码,适用于处理无序的名义类别变量。它的核心思想是:将一个类别变量转换为 N 个新的二元(0 或 1)特征列,其中 N 是该变量中类别的数量。
pd.get_dummies()
| 参数 | 描述 | 默认值 | 关键作用 |
|---|---|---|---|
data |
要进行编码的 Series}或 DataFrame。 | - | 输入待编码的数据。 |
columns |
DataFrame 中需要编码的列名列表。 | None | 精确控制对哪些列进行编码。 |
prefix |
用于附加到新列名(如 Color_Red})开头的字符串。 | None | 方便区分新生成的特征列。 |
drop_first |
是否删除第一个生成的类别列。 | False | 避免多重共线性,对线性模型(如线性回归、逻辑回归)推荐设为 True。 |
dummy_na |
是否为缺失值 NaN 创建一个单独的 dummy 列。 | False | 当缺失值本身具有信息时,设为 True。 |
drop_first
假设有一个关于“颜色”的DataFrame:
1 | |
示例 A: 基础编码 (drop_first=False)
1 | |
| Item | Color_Red | Color_Blue | Color_Green |
|---|---|---|---|
| A | 1 | 0 | 0 |
| B | 0 | 1 | 0 |
| C | 0 | 0 | 1 |
| D | 1 | 0 | 0 |
示例 B: 编码并删除第一列 (drop_first=True)
推荐删除一列的主要原因是为了避免多重共线性(Multicollinearity)。
删除按类别值排序后的第一个类别所对应的第一列,排序(字母): Blue—-Green—-Red,删除Blue
| Item | Color_Red | Color_Green |
|---|---|---|
| A | 1 | 0 |
| B | 0 | 0 |
| C | 0 | 1 |
| D | 1 | 0 |
最后 0 0就表示Blue
最终合并
1 | |
VS
1 | |
- 这两行代码最终都是把one-hot编码合并到原来的df中了
- 但是有两个微小的差别
- 两行操作最终的表头中仍然会含有Embarked
- 但一行操作会自动删掉原来的表头Embarked
- 在参数上也有微小的差别,两行操作只传入了一列,所以不需要columns参数,一行操作则反之
- 如果在后续需要用到one-hot编码的新表头,则推荐采用第一种
4.5.1 标签编码
标签编码是将每个唯一的类别值映射为一个整数。
如果一个特征有 N 个不同的类别,那么这些类别会被分配到 0 到 N-1 之间的整数。
使用场景
似乎标签编码都可以用独热编码来解决
- 有序类别变量:当类别之间存在内在的、有意义的顺序或等级关系时,标签编码是合适的。模型可以理解数字 2 大于 1,且 1 大于 0 的顺序关系。
例子: 衣服尺寸 {S} < {M} < {L},教育程度 {小学} < {中学} < {大学},满意度 {不满意} < {一般} < {满意}
目标变量 :
在进行分类任务时,机器学习模型的输出 $\text{y}$ 通常需要是数值形式。此时对目标变量进行标签编码是标准做法,因为模型只是在预测一个类别 ID,并不涉及特征间的权重关系。
例子: 预测动物类别 {Cat} 0, {Dog} 1, {Bird} 2。
1 | |
4.5.2 二元编码
1 | |